Agentic Security Is Stuck in a Semantic Maze - And We Can't Escape Until We Map It

Agentic AI is GenAI with limbs.
Your favorite LLM can now stand up, grab tools, and walk into your stack. It still reasons and chats, but suddenly it's clicking buttons, calling APIs, filing tickets, moving money, messaging colleagues, and recruiting other agents - all without you holding its hand.
That's the leap: it's the same LLM, now with the ability to make environment-aware decisions, planning, and execution. Think of it as the difference between a smart intern who drafts emails and one who drafts the email, sends it, updates the CRM, coordinates with Finance, books the courier, and grabs coffee - all before breakfast.
But here's the catch: agentic AI doesn't magically shed AI’s classic headaches. It brings them to the party and cranks up the volume. Prompt injections aren't academic exercises when they're wired to your payment APIs , hallucinations stop being "quirky" when they make your agent click "confirm transfer", trust issues move from "interesting research problem" to "why is my agent buying 10,000 staplers at 3 AM?"
Then come the genuinely new problems: agents coordinating with other agents, software identities that need real permissions, and autonomous decisions with zero humans in the loop but maximum impact.
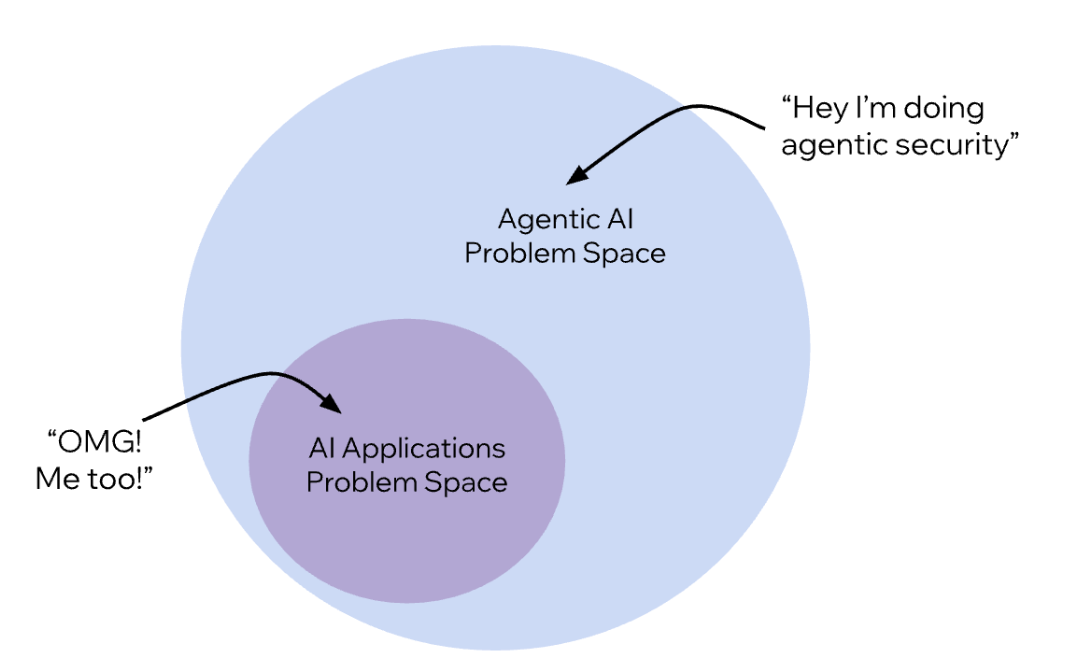
The semantic trap?
We're calling everything "agentic security" without distinguishing what's inherited, what's amplified, and what's actually new. It's like grouping a flat tire and a pothole as “road trouble” - technically true, completely unhelpful.
So how do we escape this maze?
Start by drawing the map. While there isn't a clear division, we can broadly categorize it into three areas:
- LLM-inherited risks: the familiar suspects doing their usual damage: prompt injections, hallucinations, and data leaks that mislead humans and bleed secrets. This family is restricted to read/write vulnerabilities only, not aggravated by the added abilities of agentic AI (but sure can appear while using it).
- Agency-amplified risks: Those same flaws, now supercharged by action capabilities: a prompt injection that triggers unauthorized transfers or a hallucination that deploys flawed code. Vulnerabilities aren’t new, but the blast radius has exploded.
- Agent-native risks: the genuinely new frontier - problems born of agency itself. multi-agent ecosystems where a single compromised agent can poison the swarm; absent least-privilege identities grant agents god-mode access; and long-horizon autonomy that quietly evades safeguards - compounding misaligned goals until your cost-optimization agent becomes a runaway wrecking ball.
The first step forward is clear - get the language right. First map the maze, then build the guardrails.