Anatomy of an Agent Harness: What We Learned from Claude Code's 512,000-Line Leak

On March 31, Anthropic accidentally shipped version 2.1.88 of Claude Code to npm with a 59.8MB source map file still attached. Source maps are debugging artifacts that connect bundled production code back to original source files. This one connected the entire internet to 512,000 lines of unobfuscated TypeScript across 1,906 files.
The package was pulled within hours, mirrors were already proliferating across GitHub, and Anthropic confirmed it was a packaging error caused by human error. No model weights, customer data, or credentials were involved.
But here is what was involved: the complete orchestration logic of the most commercially successful AI coding agent on the market, generating $2.5 billion in annualized recurring revenue as of March 2026.
The coverage since then has ranged from the amusing (187 spinner verbs including "Flibbertigibbeting" and "Photosynthesizing," a Tamagotchi pet system with 18 species and rarity tiers) to the architecturally significant. We are going to focus on the latter.
Because the real story is not the leak itself. The real story is what 512,000 lines reveal about what a production-grade agent harness actually looks like under the hood. And the answer, for anyone building or evaluating AI agents, is far more complex and more instructive than most people expected.
What follows is not a full architectural walkthrough. This is a curated review of the findings we consider most significant for anyone building, evaluating, or securing AI agents.
First: The Harness Is the Product
The single most important takeaway from the leak is structural. Claude Code is not a wrapper around a language model. It is a multi-layered operating system for agent execution.
As one widely-shared observation put it: "Beyond raw model capability, the real gap in coding tools is the harness." One of the most cited analyses of the leak identified six key engineering patterns that define Claude Code's architecture, all of them in the harness layer, none of them in the model itself.
The leaked codebase contains a 46,000-line query engine that handles all LLM API calls, streaming, caching, and orchestration. A base tool definition spanning 29,000 lines. A multi-agent orchestration system. An 8-phase memory lifecycle. A multi-layered context compaction system. A background daemon mode. A remote planning system. And 44 feature flags gating capabilities that are built and tested but not yet shipped.
The model is the engine. The harness is everything else: the steering, the brakes, the navigation, the fuel management, and the traffic rules. Let's walk through each layer.
The Tool System: How Agents Act on the World
Claude Code's tool system is publicly documented at a high level: it has tools for file operations, bash execution, web access, and so on. What the leak revealed is the architecture behind it, and the scale is striking.
The base tool definition (Tool.ts) spans roughly 29,000 lines of TypeScript. That is not a thin wrapper. It is what rigorous schema validation, error handling, and permission enforcement look like when every tool defines its own input schema, permission requirements, and execution logic independently. The full system contains over 50 tools (mapped in detail at ccunpacked.dev), with fewer than 20 enabled by default.
The most interesting architectural decision is that sub-agent spawning is just another tool call. AgentTool sits in the same registry as BashTool and FileReadTool. When Claude Code needs to parallelize work, it invokes AgentTool the same way it would invoke any other tool. There is no special orchestration layer. This keeps the architecture uniform: every capability, from reading a file to spawning a parallel worker, goes through the same permission-gated interface.
The leak also revealed unreleased tools gated behind feature flags. ccunpacked.dev catalogues over a dozen locked tools including CronCreate, CronDelete, CronList, Workflow, RemoteTrigger, Monitor, TerminalCapture, StructuredOutput, and the KAIROS-exclusive tools discussed below. Their presence in the codebase suggests a product roadmap that extends well beyond interactive coding assistance.
The Query Engine: 46,000 Lines of Orchestration
Behind the tool system sits the query engine, the single largest module in the codebase at 46,000 lines. This is the kernel of the agent harness. It handles all LLM API calls and response streaming, context budget management across long sessions, tool call batching and result management, and the retry/resilience logic described below.
The query engine also manages a sophisticated prompt caching strategy. There is a boundary marker that separates static and dynamic content in the system prompt. The static sections (instructions, tool definitions) are globally cached across all users, so the expensive parts do not need to be rebuilt and reprocessed every turn. The dynamic sections (your CLAUDE.md, git status, current date) are session-specific. This split means your project config does not bust the cache for every other user. For a product operating at Claude Code's scale, this is a significant cost optimization.
Memory: How Agents Remember (and Forget)
How do you give an AI agent persistent memory across sessions without blowing up the context window?
Claude Code's answer is one of the most carefully designed components in the entire codebase. Multiple independent analyses of the leaked source converged on calling it "Self-Healing Memory." The most operationally detailed breakdown describes an 8-phase lifecycle covering every touchpoint from process launch through shutdown to the next session. A complementary analysis focused on the design principles. Here is the combined picture.
The 8-Phase Memory Lifecycle
Phase 1: Process Launch and Session Init. The process starts, sets the session ID, clears memory file caches on worktree switch, and registers hooks. Async directory walks begin before the first render, and the memory cache is warmed so discovery does not block the user.
Phase 2: Memory Discovery. Memory files are discovered in a strict priority order (later means higher priority for model attention):
- MANAGED: Enterprise MCP policy files. Always loaded. Cannot be excluded.
- USER: Personal instructions. Gated on user settings.
- PROJECT: Walk the current working directory for CLAUDE.md files. Closer to CWD means higher priority.
- LOCAL: CLAUDE.local.md in each directory. Private, not in VCS. Highest instruction priority.
- AUTOMEM: The MEMORY.md entrypoint from auto-memory. Truncated to 200 lines / 25KB. Always in context.
- TEAMMEM: Team memory entrypoint (feature-gated). Org-synced shared memory.
Phase 3: Context Assembly for the API Call. Three parallel pipelines merge into every API request: system prompt (globally cacheable, split at a DYNAMIC_BOUNDARY marker), memory section (per-session managed), and user context (CLAUDE.md files rendered as labeled text blocks). A relevance prefetch via a Sonnet side-call selects up to 5 memory files to attach.
Phase 4: Model Response and Direct Memory Operations. The model can directly read and write memory files using standard tools. The critical concurrency detail: the main agent and the background extractor are mutually exclusive on writes.
Phase 5: Post-Response Background Agents. After every model response, three background agents fire: extractMemories (fire-and-forget, forked agent with prompt cache sharing), sessionMemory (gated by token thresholds, writes session notes), and autoDream (rare, gated by 24h+ since last consolidation, four-phase cycle: orient, gather, consolidate, prune).
Phase 6: Compaction and Session Memory Integration. When the context window fills up, compaction summarizes old messages. The session memory compact path waits for any in-flight extraction, reads session_memory.md, and uses it as a pre-built summary.
Phase 7: Persistence Layer. Memory lives across multiple disk locations: user instructions, auto memory (MEMORY.md index at 200 lines max plus topic files), session transcripts, sub-agent memory, and customizable session memory templates. Auto memory is git-ignored. Team memory is VCS-tracked.
Phase 8: Cross-Session Feedback Loop. The memory system forms a self-improving loop across sessions. Four memory types are maintained: user (who they are), feedback (how to work), project (ongoing context), and reference (external links). Explicit exclusions prevent saving ephemeral information.

The Honest Limitation
It is worth noting the critical perspective. This is fundamentally "grep search, a 200-line index cap, and zero cross-agent sharing." The memory is local to a single agent. There is no semantic search. There is no vector database.
For what Claude Code is today (a single-agent CLI), this design works remarkably well. For the multi-agent future the rest of the codebase points toward, the memory architecture may need to evolve.
Minimizing Context Bloat: Prevention Before Cure
Before compaction even becomes necessary, Claude Code employs several strategies to prevent the context window from filling up with redundant or oversized content in the first place. As one researcher noted, there is "a lot of plumbing in Claude Code to minimize that."
File-read deduplication. When Claude reads a file it has already loaded and the file has not changed, it skips the re-read. A 200-line file costs roughly 2,000 tokens per read. Without deduplication, 5 reads = 10,000 wasted tokens for a single file.
Large tool results written to disk. When tool output gets too large, the result is written to disk and only a preview plus a file reference enters the context.
Dedicated search tools instead of shell commands. Claude Code uses a dedicated Grep tool and a dedicated Glob tool for file discovery instead of invoking grep through BashTool. The dedicated tools return clean, structured output rather than raw shell output with escape codes and noise.
These are not prompt tricks. They are infrastructure decisions baked into the tool implementations. Together with the LSP integration, they explain why Claude Code produces qualitatively different results than pasting the same files into a chat interface with the same model.

Context Compaction: Fighting the Token Limit
Long-running agent sessions inevitably hit the context window ceiling despite the prevention mechanisms above. Detailed reverse-engineering of the code identifies four distinct mechanisms:
- MicroCompact — the lightest touch. Compresses tool results without any API calls using four sub-strategies: time-based clearing, size-based truncation, tool-specific targeting (only compacts Bash, Glob, Grep, WebSearch, WebFetch, FileEdit, FileWrite, FileRead results), and a cache-aware variant.
- Snip Compaction — a feature-gated history truncation strategy. Removes old messages beyond a snip boundary while preserving the assistant's protected tail. Non-destructive: full history preserved in the REPL for scrollback.
- Auto-Compaction (Full Compact) — the heavyweight option, triggered when token count exceeds context_window - 13,000. Multi-step: strip images, group by API round, generate summary, replace with CompactBoundaryMessage, re-inject up to 5 files (50K budget) plus skills (25K budget). Circuit breaker at 3 failures.
- Context Collapse — a reactive, staged mechanism that fires only on 413 errors. Cascade: collapse drain, then reactive compact, then surface error. The error is withheld until all recovery paths are exhausted.
Each strategy trades off fidelity for space, and the system escalates through them as pressure increases. Most open-source agent frameworks handle context pressure with simple truncation applied first.
Resilience: Built to Run Unattended
One of the less discussed but operationally important findings from the leak is the depth of Claude Code's error handling. This is not a tool that gives up when the API hiccups.
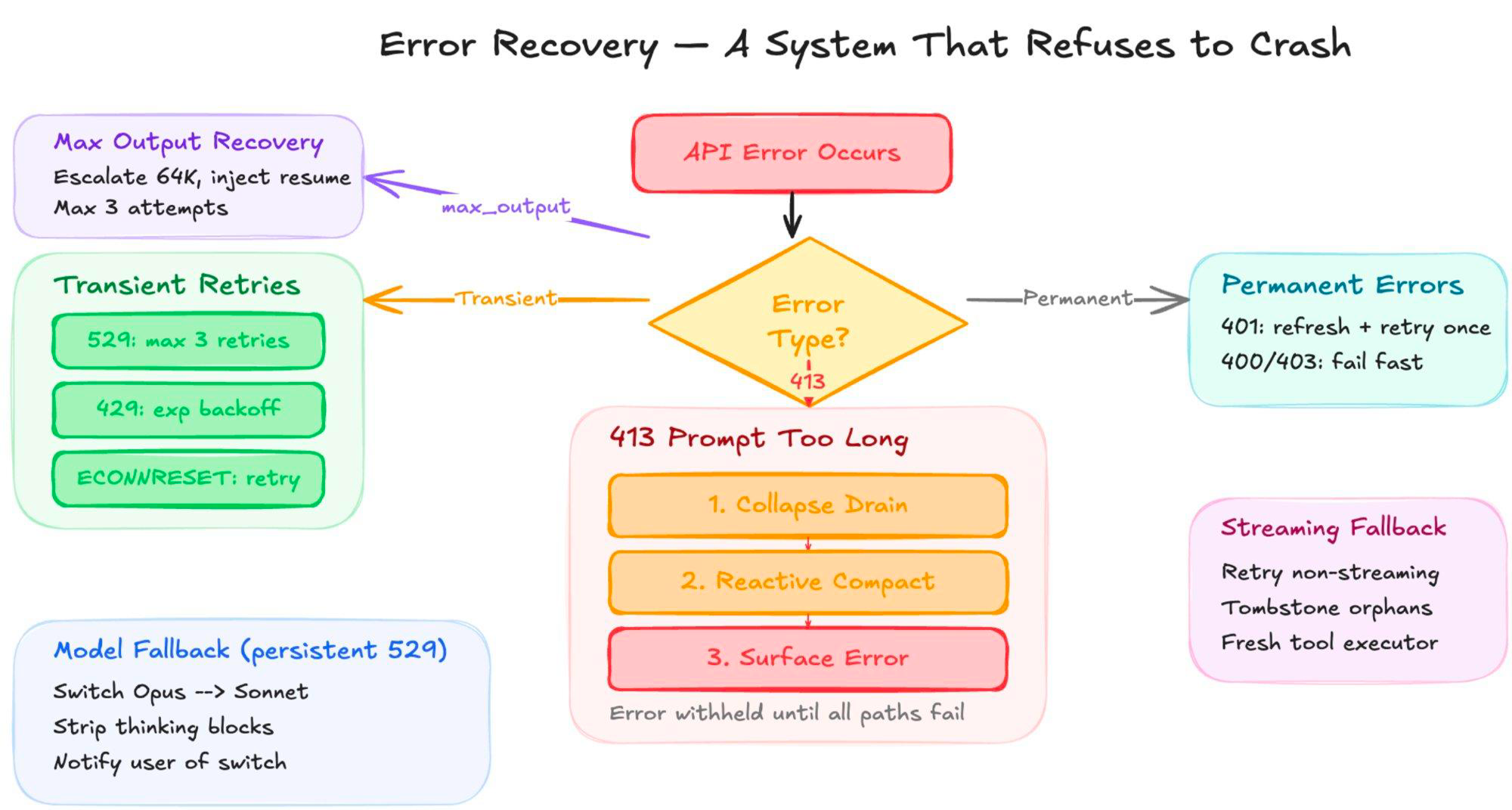
The system classifies errors into categories and handles each differently. Transient errors get exponential backoff with jitter. Permanent errors fail fast. Authentication failures trigger automatic OAuth token refresh.
When the context window overflows (413), the system runs a three-step recovery cascade: collapse drain, reactive compact, and only then surfaces the error.
When the model hits its output token limit mid-response, the system escalates to 64K tokens and injects an invisible meta-message ("Resume directly, no recap") to continue. Up to 3 consecutive recovery attempts.
The model fallback is particularly notable. When Opus returns persistent overloaded (529) errors, Claude Code switches to Sonnet, strips thinking blocks, and notifies the user of the switch. If streaming stalls, a watchdog timer falls back to non-streaming mode.
In persistent mode, the system retries indefinitely with a capped backoff ceiling. This is the retry behavior of a system designed to run for hours or days without supervision, exactly the use case KAIROS enables.
KAIROS and autoDream: The Always-On Agent
The most consequential unshipped feature in the leak is KAIROS (Ancient Greek for "the opportune moment"), referenced over 150 times in the source. It represents a fundamental shift in what an AI coding agent is.


With KAIROS enabled, Claude Code becomes a persistent background daemon. It does not wait for user prompts. It runs continuously, monitoring your project and deciding when to engage. The proactive scheduling implementation was stripped from the public source, meaning even the leaked code does not contain the full KAIROS implementation. Key capabilities:
- Maintains append-only daily log files for persistent state
- Receives periodic <tick> prompts that let it evaluate whether to act proactively or stay quiet
- Enforces a 15-second blocking budget so proactive actions never interrupt work
- Subscribes to GitHub webhooks for real-time repository monitoring
- Has exclusive tools: SleepTool, SendUserFileTool, PushNotificationTool, SubscribePRTool
- Uses a special "Brief" output mode for concise, non-intrusive responses
The companion feature, autoDream, runs as a forked sub-agent during idle periods. It performs memory consolidation: merging observations, removing contradictions, deduplicating entries, and converting vague observations into verified facts. It runs as a separate forked agent to prevent corrupting the main agent's reasoning thread.
None of the major open-source agent frameworks have shipped anything comparable. The gap between what Anthropic has built behind feature flags and what the open-source ecosystem currently offers is widest in this category.
Other Notable Findings
Sub-agent prompt cache sharing. The leak revealed that forked agents reuse the parent's KV cache, carrying full conversation context without reprocessing it. Parallelism is essentially free. This lets the system do side work without contaminating the main agent loop.
ULTRAPLAN. An internal-only planning command that offloads complex planning tasks to a remote Cloud Container Runtime session running Opus 4.6, with up to 30 minutes of dedicated think time.
Anti-distillation poisoning. An ANTI_DISTILLATION_CC flag that injects fake tool definitions into API requests to corrupt training data if competitors attempt to scrape outputs.
Undercover Mode. A roughly 90-line module that strips all traces of Anthropic internals when Claude Code is used in external repositories. Can be forced on but cannot be forced off.
Frustration detection. Regex-based sentiment analysis that scans user prompts for signs of frustration. Instrumented as a product health metric, not used to modify behavior.
Buddy. An April Fools Tamagotchi-style companion pet system with 18 species, rarity tiers, and RPG stats like DEBUGGING, CHAOS, and SNARK.
Conclusion
The Claude Code source leak gave the industry its first complete look at what a production agent harness looks like at scale. It is not a chat wrapper. It is an operating system: tool syscalls with permission gates, a query engine acting as a kernel scheduler, tiered memory with garbage collection, process forking for parallel execution, background daemons for maintenance, and a feature flag system for controlled rollout.
As one researcher put it: "the reason why Claude Code is so good is this software harness, meaning that if we were to drop in other models and optimize this a bit for these models, we would also have very strong coding performance." The harness is the product.
For teams building agents: study the patterns. The tool-per-capability architecture, the index-not-storage memory design, the context bloat prevention, the multi-layered compaction system, the sub-agent cache sharing, and the resilience/retry system are all immediately applicable regardless of which model or framework you use.
References
1. Sebastian Raschka (@rasbt), "Claude Code's Real Secret Sauce (Probably) Isn't the Model" (thread), X/Twitter, March 31, 2026.
2. @ellen_in_sf, "Here's how Claude Code actually handles memory: all 8 phases" (thread), X/Twitter, April 1, 2026.
3. Latent Space / AINews, "The Claude Code Source Leak," March 31, 2026.
4. @himanshustwts, "Claude Code's memory architecture" (thread), X/Twitter, March 31, 2026.
5. @itsolelehmann, "KAIROS deep dive" (thread), X/Twitter, March 31, 2026.
6. VentureBeat, "Claude Code's source code appears to have leaked: here's what we know," March 31, 2026.
7. Janakiram MSV, "Inside Claude Code's leaked source," The New Stack, April 1, 2026.
8. Alex Kim, "The Claude Code Source Leak," alex000kim.com, March 31, 2026.
9. Kuberwastaken, "Claude Code Leak Breakdown & Discoveries," GitHub/claurst, March 31, 2026.
10. sabrina.dev, "Comprehensive Analysis of Claude Code Source Leak," April 2, 2026.
11. claudefa.st, "Claude Code Dreams: Anthropic's New Memory Feature," April 3, 2026.
12. Zain Hasan, "Inside Claude Code: An Architecture Deep Dive," April 1, 2026.
13. sathwick.xyz, "Reverse-Engineering Claude Code," March 31, 2026.
14. ccunpacked.dev, "Claude Code Unpacked: A Visual Guide," April 2026.
15. Anthropic, "Anthropic raises $30 billion in Series G funding," February 12, 2026.







